

Cela vous aidera grandement à réfléchir aux moteurs de stockage et aux capacités qu'ils apportent à MySQL si vous avez une bonne image mentale de leur place. La figure 1 fournit une vue logique de MySQL. Cela ne reflète pas nécessairement la mise en œuvre de bas niveau, qui est forcément plus compliquée et moins claire. Cependant, il sert de guide qui vous aidera à comprendre comment les moteurs de stockage s'intègrent à MySQL. (Le moteur de stockage NDB a été ajouté à MySQL juste avant l'impression de ce livre. Surveillez-le dans la deuxième édition.)
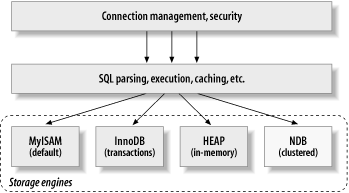
Figure 1 - Une vue logique de l'architecture MySQL
La couche supérieure est composée des services qui ne sont pas propres à MySQL. Ce sont les services dont la plupart des outils ou serveurs client/serveur basés sur le réseau ont besoin : gestion des connexions, authentification, sécurité, etc.
La deuxième couche est celle où les choses deviennent intéressantes. Une grande partie des cerveaux de MySQL vivent ici, y compris l'analyse des requêtes, l'analyse, l'optimisation, la mise en cache et toutes les fonctions intégrées (dates, heures, mathématiques, cryptage, etc.). Toute fonctionnalité fournie par les moteurs de stockage vit à ce niveau. Les procédures stockées, qui arriveront dans MySQL 5.0, résident également dans cette couche.
La troisième couche est constituée de moteurs de stockage. Ils sont responsables du stockage et de la récupération de toutes les données stockées "dans" MySQL. Comme les différents systèmes de fichiers disponibles pour Linux, chaque moteur de stockage a ses propres avantages et inconvénients. La bonne nouvelle est que de nombreuses différences sont transparentes au niveau de la couche de requête.
L'interface entre les deuxième et troisième couches est une API unique non spécifique à un moteur de stockage donné. Cette API est composée d'environ 20 fonctions de bas niveau qui effectuent des opérations telles que "commencer une transaction" ou "récupérer la ligne contenant cette clé primaire", etc. Les moteurs de stockage ne traitent pas SQL et ne communiquent pas entre eux ; ils répondent simplement aux demandes des niveaux supérieurs de MySQL.
Verrouillage et simultanéité
Le premier de ces problèmes est de savoir comment gérer la concurrence et le verrouillage. Dans tout référentiel de données, vous devez être prudent lorsque plusieurs personnes, processus ou clients doivent modifier des données en même temps. Considérons, par exemple, une boîte de messagerie classique sur un système Unix. Le format de fichier populaire mbox est incroyablement simple. Les e-mails sont simplement concaténés les uns après les autres. Ce format simple facilite la lecture et l'analyse des messages électroniques. Cela facilite également la livraison du courrier : ajoutez simplement un nouveau message à la fin du fichier.
Mais que se passe-t-il lorsque deux processus essaient de livrer des messages en même temps à la même boîte aux lettres ? Il est clair que cela peut corrompre la boîte aux lettres, laissant deux messages entrelacés à la fin du fichier de boîte aux lettres. Pour éviter la corruption, tous les systèmes de livraison de courrier bien comportés implémentent une forme de verrouillage pour empêcher la livraison simultanée de se produire. Si une seconde remise est tentée alors que la boîte aux lettres est verrouillée, le second processus doit attendre de pouvoir acquérir le verrou avant de remettre le message.
Ce schéma fonctionne raisonnablement bien dans la pratique, mais il fournit une simultanéité plutôt médiocre. Étant donné qu'un seul programme peut apporter des modifications à la boîte aux lettres à un moment donné, cela devient problématique avec une boîte aux lettres à volume élevé, qui reçoit des milliers de messages par minute. Ce verrouillage exclusif fait en sorte qu'il est difficile pour la distribution du courrier de ne pas être retardée si quelqu'un tente de lire, de répondre et de supprimer des messages dans cette même boîte aux lettres. Heureusement, peu de boîtes aux lettres sont aussi occupées.
Verrouillages en lecture/écriture
La lecture à partir de la boîte aux lettres n'est pas aussi gênante. Il n'y a rien de mal à ce que plusieurs clients lisent simultanément la même boîte aux lettres. Puisqu'ils ne font pas de changements, rien ne risque de mal tourner. Mais que se passe-t-il si quelqu'un essaie de supprimer le message numéro 25 pendant que des programmes lisent la boîte aux lettres ? Ça dépend. Un lecteur pourrait repartir avec une vue corrompue ou incohérente de la boîte aux lettres. Ainsi, pour être sûr, même la lecture à partir d'une boîte aux lettres nécessite une attention particulière.
Les tables de base de données ne sont pas différentes. Si vous considérez chaque message électronique comme un enregistrement et la boîte aux lettres elle-même comme une table, il est facile de voir que le problème est le même. À bien des égards, une boîte aux lettres n'est en réalité qu'une simple table de base de données. La modification d'enregistrements dans une table de base de données est très similaire à la suppression ou à la modification du contenu des messages dans un fichier de boîte aux lettres.
La solution à ce problème classique est assez simple. Les systèmes qui gèrent un accès simultané en lecture/écriture implémentent généralement un système de verrouillage composé de deux types de verrous. Ces verrous sont généralement appelés verrous partagés et verrous exclusifs ou verrous en lecture et verrous en écriture.
Sans nous soucier de la technologie de verrouillage proprement dite, nous pouvons décrire le concept comme suit. Les verrous en lecture sur une ressource sont partagés : de nombreux clients peuvent lire à partir de la ressource en même temps et ne pas interférer les uns avec les autres. Les verrous en écriture, en revanche, sont exclusifs, car il est sûr d'avoir un seul client écrivant sur la ressource à un moment donné et d'empêcher toutes les lectures lorsqu'un client écrit. Pourquoi? Parce que l'auteur unique est libre d'apporter des modifications à la ressource, voire de la supprimer entièrement.
Dans le monde des bases de données, le verrouillage se produit tout le temps. MySQL doit empêcher un client de lire une donnée pendant qu'un autre la modifie. Il effectue cette gestion de verrouillage en interne de manière transparente la plupart du temps.
Verrouiller la granularité
Une façon d'améliorer la simultanéité d'une ressource partagée consiste à être plus sélectif sur ce qui est verrouillé. Plutôt que de verrouiller la totalité de la ressource, verrouillez uniquement la partie qui contient les données que vous devez modifier. Mieux encore, verrouillez uniquement la donnée exacte que vous prévoyez de modifier. En diminuant la quantité de données verrouillées à tout moment, davantage de modifications peuvent se produire simultanément, tant qu'elles n'entrent pas en conflit les unes avec les autres.
L'inconvénient est que les verrous ne sont pas gratuits. Il y a une surcharge impliquée dans l'obtention d'un verrou, la vérification pour voir si un verrou est libre, la libération d'un verrou, etc. Toute cette affaire de gestion des verrous peut vraiment commencer à éroder les performances car le système passe son temps à gérer les verrous au lieu de stocker et de récupérer des données. (Des choses similaires se produisent lorsque trop de responsables sont impliqués dans un projet logiciel.)
Pour obtenir les meilleures performances globales, une sorte d'équilibre est nécessaire. La plupart des serveurs de bases de données commerciaux ne vous donnent pas beaucoup de choix : vous obtenez ce qu'on appelle un verrouillage au niveau des lignes dans vos tables. MySQL, en revanche, offre un choix en la matière. Parmi les moteurs de stockage parmi lesquels vous pouvez choisir dans MySQL, vous trouverez trois granularités de verrouillage différentes. Jetons un coup d'œil à eux.
Table locks
La stratégie de verrouillage la plus basique et la moins coûteuse disponible est un verrou de table, qui est analogue aux verrous de boîte aux lettres décrits précédemment. La table dans son ensemble est verrouillée sur une base tout ou rien. Lorsqu'un client souhaite écrire dans une table (insertion, suppression ou mise à jour, etc.), il obtient un verrou en écriture qui maintient toutes les autres opérations de lecture ou d'écriture à distance pendant la durée de l'opération. Une fois l'écriture terminée, la table est déverrouillée pour permettre à ces opérations en attente de se poursuivre. Lorsque personne n'écrit, les lecteurs obtiennent des verrous en lecture qui permettent aux autres lecteurs de faire de même.
Pendant longtemps, MySQL n'a fourni que des verrous de table, ce qui a suscité beaucoup d'inquiétudes parmi les geeks des bases de données. Ils ont averti que MySQL ne se développerait jamais au-delà des projets de jouets et ne fonctionnerait pas dans le monde réel. Cependant, MySQL est tellement plus rapide que la plupart des bases de données commerciales que le verrouillage des tables ne gêne pas autant que les opposants l'avaient prédit.
Une partie de la raison pour laquelle MySQL ne souffre pas autant que prévu est que la majorité des applications pour lesquelles il est utilisé consistent principalement en des requêtes de lecture. En fait, le moteur MyISAM (par défaut de MySQL) a été construit en supposant que 90 % de toutes les requêtes exécutées sur lui seront lues. Il s'avère que les tables MyISAM fonctionnent très bien tant que le rapport des lectures aux écritures est très élevé ou très faible.
Verrouillage des pages
Une forme de verrouillage légèrement plus coûteuse qui offre une plus grande simultanéité que le verrouillage de table, un verrou de page est un verrou appliqué à une partie d'une table connue sous le nom de page. Tous les enregistrements qui résident sur la même page de la table sont affectés par le verrou. En utilisant ce schéma, le principal facteur influençant la concurrence est la taille de la page ; si les pages du tableau sont grandes, la simultanéité sera pire qu'avec des pages plus petites. Les tables BDB (Berkeley DB) de MySQL utilisent le verrouillage au niveau de la page sur les pages de 8 Ko.
Le seul point sensible du verrouillage de page est la dernière page du tableau. Si des enregistrements y sont insérés à intervalles réguliers, la dernière page sera verrouillée fréquemment.
Row locks
Le style de verrouillage qui offre la plus grande simultanéité (et entraîne la plus grande surcharge) est le verrou de ligne. Dans la plupart des applications, il est relativement rare que plusieurs clients aient besoin de mettre à jour exactement la même ligne en même temps. Le verrouillage au niveau des lignes, comme on l'appelle communément, est disponible dans les tables InnoDB de MySQL. Cependant, InnoDB n'utilise pas un simple mécanisme de verrouillage de ligne. Au lieu de cela, il utilise le verrouillage au niveau de la ligne en conjonction avec un schéma de multiversion, alors regardons cela.
Contrôle de la concurrence multi-versions
Il existe une dernière technique pour augmenter la concurrence : le contrôle de la concurrence multi-versions (MVCC). Souvent appelé simplement gestion des versions, MVCC est utilisé par Oracle, par PostgreSQL et par le moteur de stockage InnoDB de MySQL. MVCC peut être considéré comme une nouvelle variante du verrouillage au niveau des lignes. Il a l'avantage supplémentaire de permettre des lectures non bloquantes tout en verrouillant les enregistrements nécessaires uniquement pendant les opérations d'écriture. Certaines des autres propriétés de MVCC seront d'un intérêt particulier lorsque nous examinerons les transactions dans la section suivante.
Alors, comment fonctionne ce schéma ? Conceptuellement, toute requête sur une table verra en fait un instantané des données telles qu'elles existaient au moment où la requête a commencé, quel que soit le temps d'exécution. Si vous n'avez jamais vécu cela auparavant, cela peut sembler un peu fou. Mais donnez-lui une chance.
Dans un système de contrôle de version, chaque ligne est associée à deux valeurs masquées supplémentaires. Ces valeurs représentent quand la ligne a été créée et quand elle a expiré (ou supprimée). Plutôt que de stocker l'heure réelle à laquelle ces événements se produisent, la base de données stocke le numéro de version au moment où chaque événement s'est produit. La version de la base de données (ou version du système) est un nombre qui s'incrémente à chaque fois qu'une requête[1] commence. Nous appellerons ces deux valeurs l'identifiant de création et l'identifiant de suppression.
[1] Ce n'est pas tout à fait vrai. Comme vous le verrez lorsque nous commencerons à parler des transactions plus tard, le numéro de version est incrémenté pour chaque transaction plutôt que pour chaque requête.
Sous MVCC, une dernière tâche du serveur de base de données est de garder une trace de toutes les requêtes en cours d'exécution (avec leurs numéros de version associés). Voyons comment cela s'applique à des opérations particulières :
SELECT
Lorsque des enregistrements sont sélectionnés dans une table, le serveur doit examiner chaque ligne pour s'assurer qu'elle répond à plusieurs critères :
- Son identifiant de création doit être inférieur ou égal au numéro de version du système. Cela garantit que la ligne a été créée avant le début de la requête en cours.
- Son identifiant de suppression, s'il n'est pas nul, doit être supérieur à la version actuelle du système. Cela garantit que la ligne n'a pas été supprimée avant le début de la requête en cours.
- Son ID de création ne peut pas figurer dans la liste des requêtes en cours d'exécution. Cela garantit que la ligne n'a pas été ajoutée ou modifiée par une requête en cours d'exécution.
- Les lignes qui réussissent tous ces tests peuvent être renvoyées comme résultat de la requête.
INSERT
- Lorsqu'une ligne est ajoutée à une table, le serveur de base de données enregistre le numéro de version actuel avec la nouvelle ligne, en l'utilisant comme ID de création de la ligne.
DELETE
- Pour supprimer une ligne, le serveur de base de données enregistre le numéro de version actuel comme identifiant de suppression de la ligne.
UPDATE
- Lorsqu'une ligne est modifiée, le serveur de base de données écrit une nouvelle copie de la ligne, en utilisant le numéro de version comme ID de création de la nouvelle ligne. Il écrit également le numéro de version comme identifiant de suppression de l'ancienne ligne.
